So, this was a tough one. MarcEdit has a right-to-left data entry mode that was created primary for users that are creating bibliographic records primarily in a right to left language. But what happens when you are mixing data in a record from left-to-right languages like English and Right-to-left languages, like Hebrew. Well, in the display, odd things happen. This is because of what the operating system does when rendering the data. The operating system assumes certain data belongs to the right-to-left string, and then moves data in a way that it think it should render. Here’s an example:
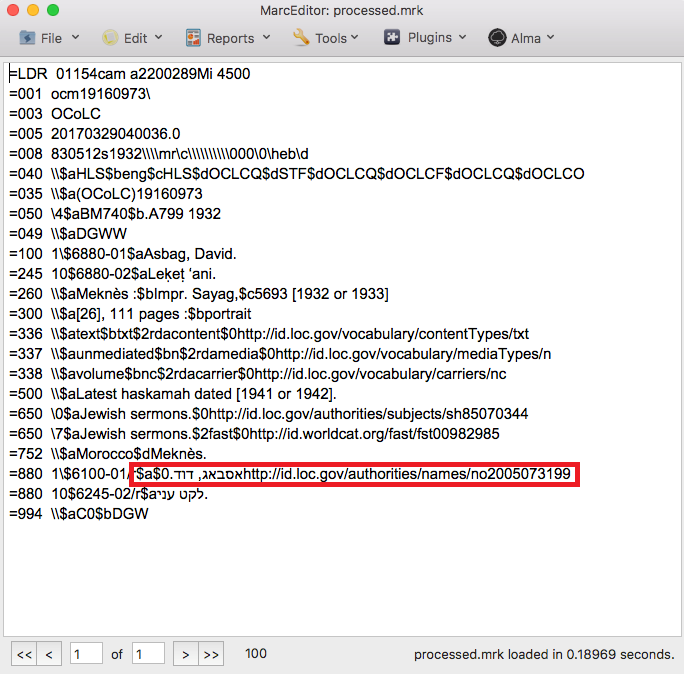
In this example, the $a$0 are displayed side-by-side, but this is just a display issue. Underneath, the data is really correct. If you compiled this data or loaded into an ILS, the data would parse correctly (though, how it displayed would be up to the ILS support of the language). But this is confusing, but unfortunately, one of the challenges of working with records in a notepad-like environment.
Now, there is a solution that can solve the display problem. There are two Unicode characters 0x200E and 0x200F — these are Left-to-right character markers and Right-to-left character markers. These can be embedded in the display to render characters more appropriately. They only show up in the display (i.e. are added when reading into the display), and are not preserved in the MARC record. They help to alleviate some of these problems.
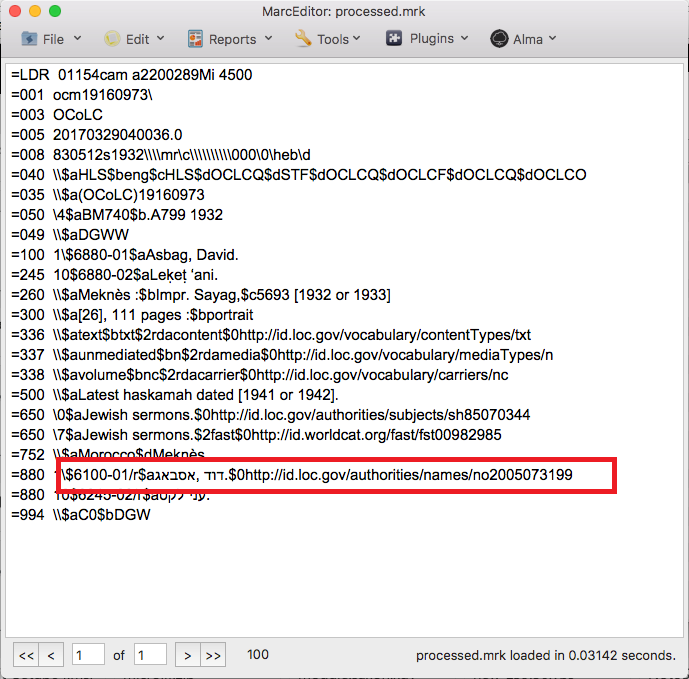
The way that this works — when the program identifies that its working with UTF8 data, the program will screen the text for characters have a byte that indicate that they should be rendered RTL. The program will then embed a RTL marker at the beginning of the string and a LTR marker at the end of the string. This gives the operating system instructions as to how to render the data, and I believe helps to solve this issue.
–tr
Comments
One response to “MarcEditor Changes and Right-to-left displays”
[…] I believe that there will need to be a couple additional updates around the alma work — particularly when creating new holdings, as I’m not seeing the 001/004 pairs added to the records, but this is the start of that work. Also, I did some work around right-to-left, left-to-right rendering when working with mixed languages. See: https://blog.reeset.net/archives/2103 […]