I’ve been having some folks ping me recently regarding how data is displayed in the Z39.50 client. To simply the data display process, I pull data into a byte array and simply render the content using the Windows 1252 codepage. This means that any data returned via UTF8 (which I certainly don’t see often) gets flattened in the display. When you download the record, the data is saved correctly, its just the display that’s affected.
Well, folks have been wanting to see this corrected. So, I spent some time this evening and think that I got it. Here’s an example of how unicode data now appears in the new Z39.50 client. Querying an Israeli union list that includes a number of MARC records in Hebrew, we now see the following in display field.
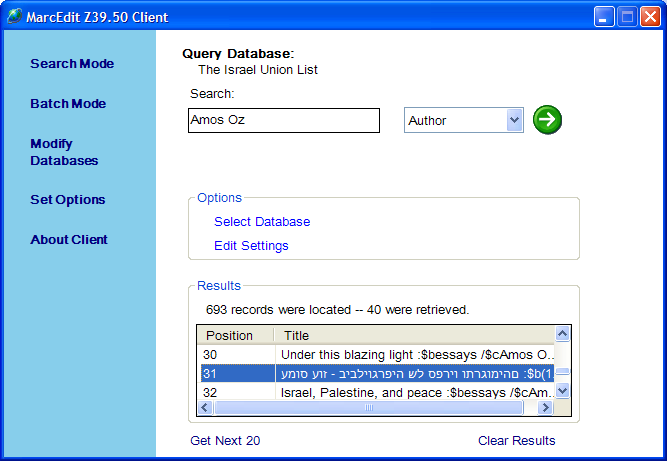
You can see that the Hebrew now appears in the display field (if the data is returned in Unicode). When you click on this record for edit, you also see the Hebrew in the Record Editor (this was always the case with the full MarcEditor):
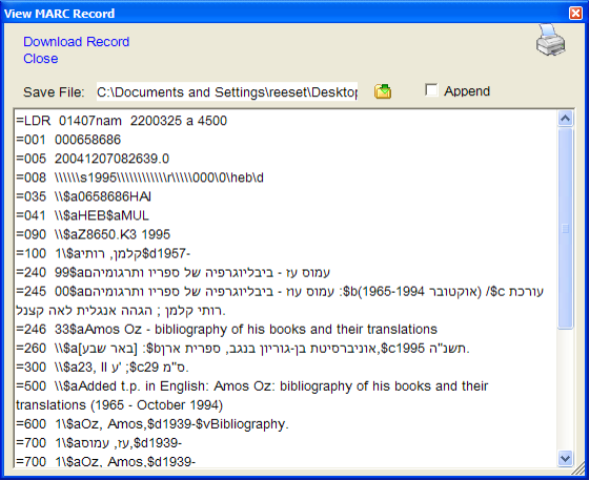
I’m pretty sure this will make life a bit easier for my international users. I’m releasing this change without doing a lot of testing in part because I don’t have a unicode resource to test off of. So if you are using MarcEdit and have a Z39.50 server that returns data in UTF8, give it a while and let me know if you run into any problems.
Other updates:
- Find/Replace — removed some of the mousing necessary to use this function
- Z39.50 Client — unlocked the record view pane to allow for inline edit.
- Z39.50 Client UI changes — allow font and diacritic settings set in MarcEdit proper to be respected in the Z39.50 Client.
You can download the update from: MarcEdit50_Setup.exe
–TR