It’s been about a month since the last update, so I’ve got a whole slew of changes to note with this update. However, before noting the things that are fixed, I should note the things that are enhanced. Over the last month, I’ve written ~10,000 new lines of code to continue to work to make MarcEdit a bit more friendly for it’s international userbase. One of the things that I find surprising sometimes is that more international users don’t use UTF8 when describing their MARC data. Most (and I actually blame this on the US since we have seemed to be very unicode adverse up to a few years ago when in came to software design) international users I speak to require a tool that can utilize a wide variety of codepages, rather than the ability to work with MARC8 or UTF8. For example, recently I was asked about allowing MarcEdit to convert data from UTF8 and MARC8 to GBK or codepage 936 (Simplified Chinese). For international users I have always assumed that most would have simply gravitated to UTF8, and oddly, this doesn’t seem to always be the case.
So, the question that consistantly comes up is how can I user MarcEdit with records using these types of datasets? Does MarcEdit support them? The short answer has always been, yes, but… The MARCEngine itself is fairly data agnostic. It reads data at a bit level and can handle any character encoding. It works best with UTF8 data, can convert UTF and MARC8 data back and forth, but will work fine with other encodings. The trick is to turn off the diacritics processing so you can view your mnemonic file within a different file editor. Otherwise, MarcEdit will replace characters with mnemonics — creating a funky looking file that borders on unusable. Generally, when folks asked me these questions, I would give them the advice above, primarily because the MarcEditor had only supported UTF8. MarcEdit’s MarcEditor was designed specifically to read the mnemonic or UTF8 formated data — so data in other charactersets (including raw MARC8 — which is why I use mnemonics) where flattened, losing diacritics. A problem for folks that wanted to use alternative character encodings.
With that in mind, I’ve spent the last month reworking much of the code in the MarcEditor and ancillary functions so now users can specify the default codepage to be used by the MarcEditor. This allows someone using GBK to specify that as the MarcEditor codepage and voila, the program will now allow you to open, edit and save data using that codepage. Pretty cool. Here’s exactly how it works (it requires the setting of two option values).
- Open MarcEdit and select Preferences
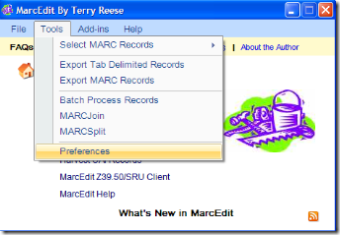
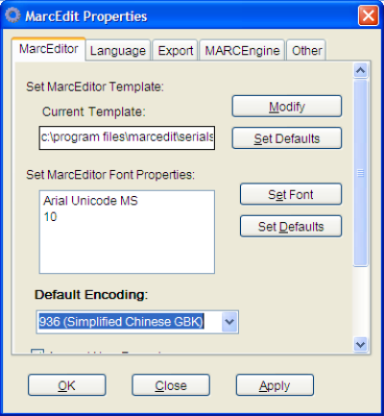
- From preferences, first select the MarcEditor tab and chance the default encoding from UTF8 to your preferred encoding (for this sample, we’ll choose simplified chinese).
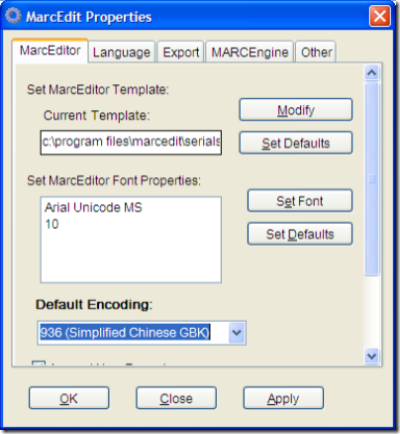
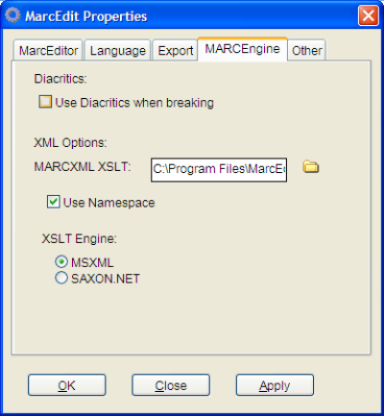
- Next, we need to tell the MARCEngine to stop using diacritics (i.e., swapping out non-UTF8 values to mnemonic equivalents). Click on the MARCEngine Tab and uncheck the use diacritic checkbox.
- Click OK
And that’s it. At this point, MarcEdit’s MarcEditor will configure itself to utilize that codepage each time you open and try to edit a file with it. More importantly, all the ancillary functions will be configured to use that codepage as well.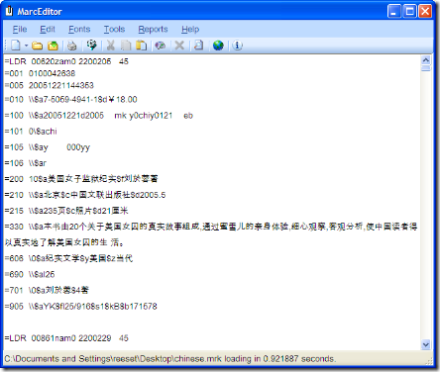
So that was a big change for the application. This required a lot of new code, but allowed me to do a number of things once it was finished. For example, I’ve been able to change the character conversion function to allow users to convert from one format to another, rather than from one codepage into UTF8 or MARC8.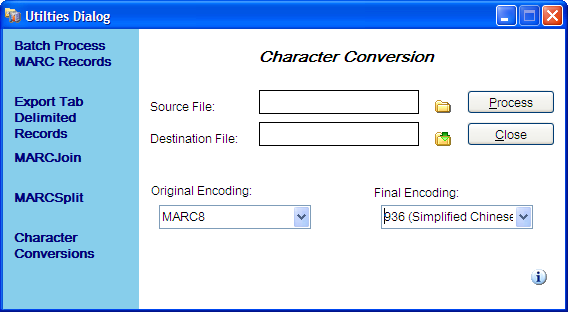
Anyway, I hope that someone finds these enhancements worthwhile and will make MarcEdit a little bit easier to use for it’s international user community.
Other enchancements:
Outside of the internationalization code, I’ve been working to squash a number of problems reported to me over the past few weeks. In no particular order, here’s what’s been taken care of with this update.
- Delimited Text Wizard:
- First, I can’t remember if I announced this, but you can now join (or build relationships) between fields that you are creating within the wizard. This is done by selecting and then right clicking on a group of items (see below).
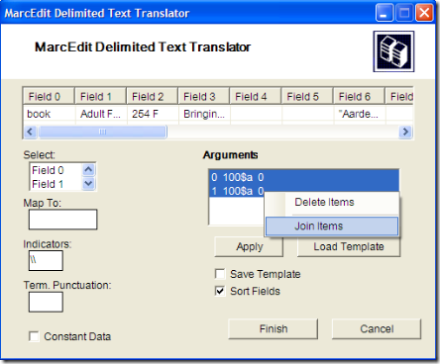
- Related to the above, when joining fields that included a non-joined field, the joined fields subfields would be ignored. So, for example, if you had 3 fields and you wanted to create an 852$j, and join two fields and create an 852$p from the joined data, you would get an output that didn’t include the $p, just the data. This has been corrected.
- Additionally, when revising this code, I found that if the joined values didn’t exist or the line didn’t include enough fields and one of the dropped values was a joined field, then the entire line would be omitted. This has been corrected.
- UTF8 support has been added. You can now tell the Delimited Text Translator if the source file is in UTF8 or not (by default, this shouldn’t be assumed since Excel doesn’t export in UTF8 by default)
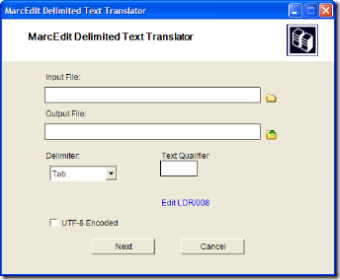
- Few tweaks to the delimited parsing code to take into account some of the additional funkiness of excel generated data. This primarily relates to data that includes new lines within the delimited data (I hate when that happens)
- Character Conversions:
- The aforementioned character conversion changes have occurred. In the process, I consoladated the MARC8=>UTF8 and UTF8=>MARC8 tools, so now they are all one function. You will still see the separate menu entries in the MARC Tools window, but they all point to the same area — just some of the values are pre-selected for you.
- MarcEditor:
- Internationalization support
- Swap Field function: When moving data from a variable field to a control field (for example, the 035 to the 001), the following data errors could have occurred.
- If moving data without finding specific text, the field would be moved to the control field, minus the first value in the field. That has been corrected.
- If moving data while trying to find a specific text value in the field, the swap would always fail. This has been created.
- As a side not, the swap field function will be one area that I will likely refactor in the near future.
- Find/Replace with ungodly large files would cause the application to hang.
- When I investigated this problem, it seemed to be related to the version of the RichText Control being utilized by the .NET framework. While Microsoft’s XP and Vista operating systems use the Version 5 components by default, the .NET framework defaults to the 2.0 version of the RichText Controls. This definitely explained some of the other problems that I occasionally see. So, to fix this, I’ve added a new class that will determine what the most current version of the RichText control you have on your machine — and will use that one. One my XP machine, this solved the Find/Replace problem.
- Recent Files List — I’d noted this in a quick fix, but I have formally fixed the Recent files list issue. The issue was related to the code trying to read past an array boundary.
- Generate Control Numbers: This has been enhanced so you can have the program generate control numbers for an existing file, not just create new ones for new files.
- Plugin framework. I’ll talk about one of the functions I’m planning with this below — however, the idea here is that I have some special use tools that I’d like to add to MarcEdit and I don’t want to make the download larger than it already is. Because of that, I’m going to start release some elements as plugins. There will be a plugin manager within the application to allow you to download, update, delete plugins, as well as some specs. on building them yourself. Very likely, a few existing tools will likely be re-worked as plugins (though that may come later).
- MARC Tools:
- I’ve had reports of folks not being able to unminimize this window. The problem is related to the program saving windows screen coordinates and not a reference to window state. When you close the window while minimized, windows passes the screen corrdinatates of -32000, -32000. This is obviously off the screen. I’ve fixed this so that state is maintained.
- Updated some window dressing — when the user clicks on a file which spawns the MarcBreak/MarcMaker, the program will now remember file names when the user clicks to save a new file. I had blanked that value because I figured folks would want to give new files their own names. Apparently not in most cases.
- MARCEngine:
- Added a new Error value [raw value: -11; translates to, invalid record format for function, i.e., trying to run a mnemonic file through the breaker, etc.]
- MarcMaker function: The 000 and the LDR are functionally equivalent fields. If you had a record that included both (are there such things — who knows) the program would choke and die. Now, it tracks the presence of such fields, so if both exist in a record, it can handle it by treating the 000 as just another numeric field.
- MARC21 Objects
- Added Stream functions to allow you to edit records as streams.
- Some modifications to the Z39.50 object to add some streaming functions, better error messages.
Anyway, I think that covers everything that I’ve been working on. I need to get a formal ticketing system I think 🙂
Todo:
Speaking of a ticketing system, had I had one, I probably wouldn’t have missed two enhancements that I had on this list for this round that I missed. And unfortunately, given my schedule, likely won’t bubble into MarcEdit for a week or so. As of this point, I have the following on my todo list:
- MarcValidator: Updating the remove invalid record function to remove invalid records and save the invalid records to a separate save file for investigation.
- Verify URL: I’ve been meaning to update the threading component that runs this tool and link it and the MarcEditor together to make editing of URLs in records easier.
- MarcEdit Script Wizard
- Updating the III punctuation corrector. When users of Innovative Interfaces catalogs export their MARC records from their systems, they are facted with one of two unattractive choices.
- They can export their data so that all trailing punctuation is removed from the record (the Oregon State Library’s system is configured with this setting — ugh)
- They can export their data so that trailing punctuation is added to all fields on export (Oregon State Universities’ III system is configured with this setting — ugh)
- At present, the script wizard will fix records where every field has trailing punctuation added to it. I have source code now (because we are dealing with some records from the State Library), that puts the punctation back into the records. I know, I know – who cares if a period is missing at the end of a line. Well, catalogers (and suprisingly, occasionally users that seem to have a little too much time on their hands) do — so this will be folded into the next update as well.
- OCLC Connexion plugin: I’ve been wanting, for some time, to be able to edit files directly from the OCLC local save file in MarcEdit and save back the changes. Well, I’ve been looking at the local save file structure, and as of their current version, its basically a simple MS Access database (who wouldof thunk it). Using the generic OBDC driver in windows, you can easy read and write data to the local save file, so I think I will. This will likely be the first plugin written to test this concept, and since the only people who might be interested in it is me, it provides a good opportunity to test how these integrate within the application and can be managed with the plugin manager. One thing I’m hoping is that evetually, OCLC will open up a few more of its services so I can integrate some of the subject validation, etc. into MarcEdit for those that want that — but those types of enhancements would be up to OCLC, not I.
- Z39.50 Update: I’ve been testing code that adds the Z39.50 Extended support classes to MarcEdit. At this point, I’m just integrating it closer to the MarcEditor so users can take advantage of the editors tools before uploading items.
Downloads:
- Download Application Update (for everyone): MarcEdit51_Setup.exe
- Download Runtime Updates (for developers): MarcEdit51_Runtimes.exe
–TR
Comments
3 responses to “MarcEdit 5.1 Updates”
“One thing I’m hoping is that evetually, OCLC will open up a few more of its services so I can integrate some of the subject validation, etc. into MarcEdit for those that want that – but those types of enhancements would be up to OCLC, not I.”
Talk with Jeremy Frumkin about OCLC’s Developer Network, also see
… also see http://www.ibiblio.org/bess/?p=88
I’ll ask Jeremy about it. I’ve asked folks directly developing Connexion in the past and the answer has always been no. If this has changed, I’d certainly be happy about it.
–TR