I’ve got a couple of MarcEdit updates for folks. Most of these updates are related to the Z39.50 client. Of course, a number of other features have been added as well. Here are the highlights:
Z39.50 Changes
So a number of Z39.50 changes — some related to adding editing functionality to the MarcEditor, others to provide Unicode search support for Z39.50 queries. Big changes are:
- Unicode searches are now supported. One of the funny things about Z39.50 is that by default, it wants to perform searches in a Latin format. While there is a characterset option that can be set — few places seem to implement it. So, MarcEdit will now evaluate the search string and then translate it appropriately to allow for correct searching (at least, this has been the case with all the test servers that I’ve worked with so far).
- Auto Unicode transforms. While you can specify a return characterset — most Z39.50 servers will not send Unicode data back to you even if you ask. MarcEdit’s Z39.50 client will provide transparent character translation for you, allowing you to take data in the format returned by the server or specifying that unicode data is always returned. The way that you implement this new option is in the search screen (see below). Simply check the Unicode option and the program will ensure that the data returned to the user is UTF8 encoded.
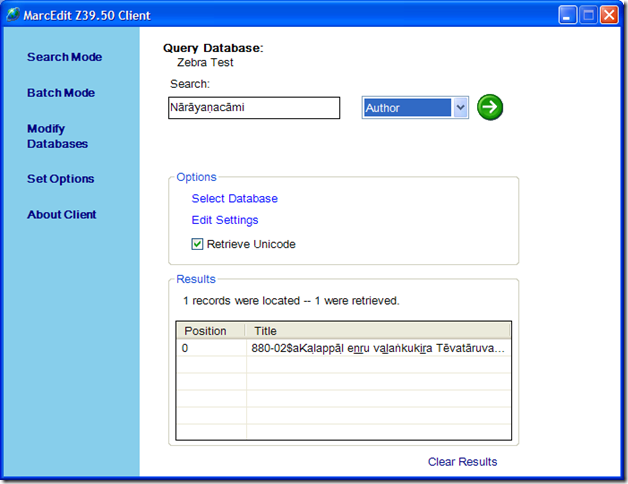
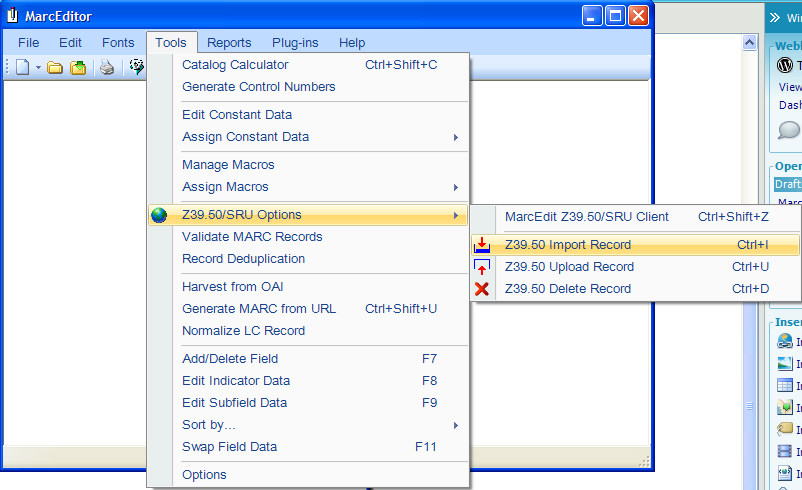
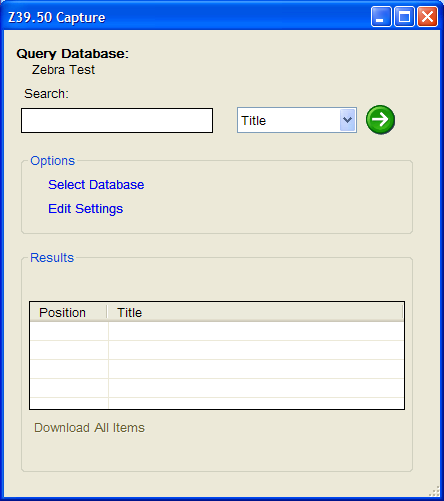
- In addition to changes to the Z39.50 Client, I’ve also included a lite-weight Z39.50 client into the MarcEditor. This has been included to allow users to edit metadata records directly against a Z39.50 Server. The new functionality is an Import, Update and Delete function. This allows you to import files or groups of files into the Editor for edit, update those files that are edited and then delete files loaded into the editor. Here are some screen shots:
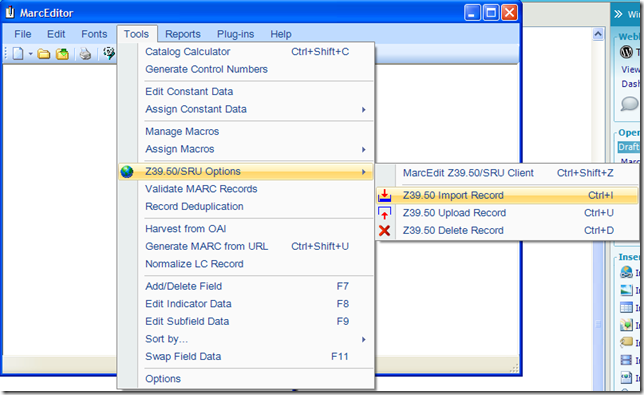
(Import Function — Initializes the Lite-weight tool)
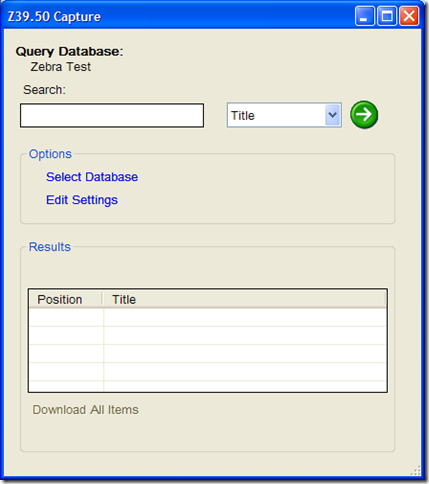
Again, this is a lite-weight tool. At this point, the Edit Settings link is disabled. If you need to change a database’s settings, you will want to update the settings using the full-blown Z39.50 tool. They pull from the same data sources. These changes will allow folks with systems like Koha or Zebra edit records directly in the MarcEditor.
Other changes
Few other changes. In the MarcEditor, you will now see the filename in the header (see below):
Also made changes to the command-line MarcEdit tool. Added a new switch, -character. This allows you to do character conversions. For example, this is how you would convert a utf8 MARC file to a MARC8 MARC file:
C:\net_marcedit\C#\MProgram\MarcEdit\bin\Debug>cmarcedit -s c:\export.mrc -d c:\export1.mrc -utf8 -character
Beginning Process…
Records have been processed.
Within the MarcEditor, also re-implemented the Select Individual Records to Make function (found in the file menu):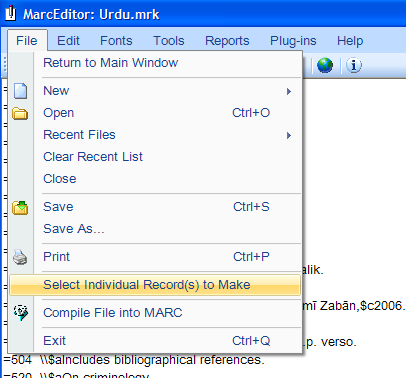
The last change of note is the Delimited Text Translator. I’ve added the ability to import data directly from an MS Access database. It works basically like Excel importing. You select the database and then select the Table/Sheet that you want to pull data from.
Download files are found at: http://oregonstate.edu/~reeset/marcedit/software/development/MarcEdit51_Setup.exe
–TR
Comments
4 responses to “MarcEdit 5.1 Update”
Yes, character sets for Z39.50 searches are a huge mess. Maybe 10% of targets I’ve tested support UTF-8 queries, 80% support Latin-1, and the other 10% are totally screwy (will only accept ASCII or something unusual like KOI-8-R or Latin-2, or will only accept certain diacritics and not others.) Sadly, the only way to figure out what encoding a server will accept is manual testing. Anyway, I feel your pain 😉
Casey,
So that’s interesting. So far in my testing (and granted, I’ve only worked with maybe 100 or so Z servers), I’ve found that UTF8 query support is indeed very few and far between, but that the method of converting data down to latin-1 seems to work fairly reliably. Would you happen to have some examples of servers that behave oddly. Would give me some test cases to work with.
–TR
Hi
Do you know if the Indian character set will ever be fully supported? Difficult I know as there are so many languages…
As far as I’m aware, the full indian characterset should be supported by MarcEdit. This was done 3 years ago now when I worked with folks at the equivalent of the National Librarian in India to ensure that MarcEdit would support record create in the 7 national scripts.