
Ah Dante – if only he had been a librarian. I’m almost certain that had the divine comedy been written by a cataloger – character encodings and those that mangle them – would definitely make an appearance. I can almost see the story in my head. Our wayward traveler, confused when our guide, Virgil, comments on the unholy mess libraries, vendors, and tool writers in general have made of the implementation of UTF-8 across the library spectrum – takes us to the 5th circle of hell filled with broken characters and undefined character boxes. But spend anytime working in metadata management today, and the problems of mixed Unicode normalizations, the false equivalency of ISO-8859-2 and UTF-8 (especially by vendors that server Western European markets), lackluster font development, and applications and programming languages that quietly and happily mangle UTF-8 data as part of general course – and you can suddenly see why we might make a stop at the lake of fire and eternal damnation.
Within MarcEdit, one of the hardest things that the application does is attempt to correct and normalize character encodings across the various known codepoints. This isn’t super easy – especially when our MARC forepersons made that fateful decision to create MARC-8, a 100% imaginary character encoding only (kind of) supported within the Library community and software. These kinds of decisions, and the desire to maintain legacy compatibility, has haunted our metadata and made working with it immensely complicated. Sometimes, these complications can be managed, other times, they are so gruesomely mangled that Brutus, himself, would cry yield. That’s what this new option will attempt to help remediate.
Through the years, I’ve often helped individuals come up with a wide variety of ways to identify invalid UTF-8 characters that litter library records. Sometimes, this can be straightforward, but more often, it’s not. To that end, I’ve attempted to provide a couple of tools that will hopefully help to identify and support some kind of remediation for catalogers haunted by the specter of bad data.
Identification
The first enhancement comes in the MARCValidator. When validating a record against the rules file, the tool will automatically attempt to determine if UTF-8 data (if present) found within a record is valid. If not, the information will be presented as a warning – identifying the field, record number, and data where the invalid data was identified.
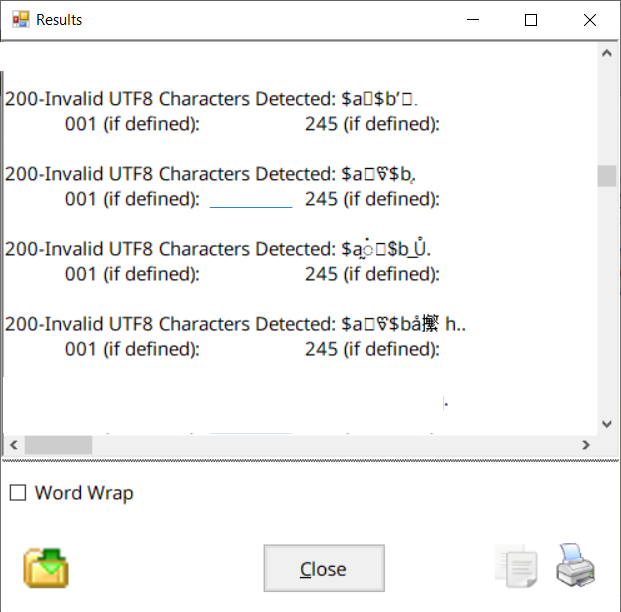
By facilitating a process to identify invalid UTF-8 record data within the validator – the idea is that this will empower catalogers looking to take a more active role in rooting out bad diacritical data before a record is loaded into the catalog and made available to the public.
Removing bad data
In addition to identification, I’ve added three new options to give users different options for dealing with invalid character data.
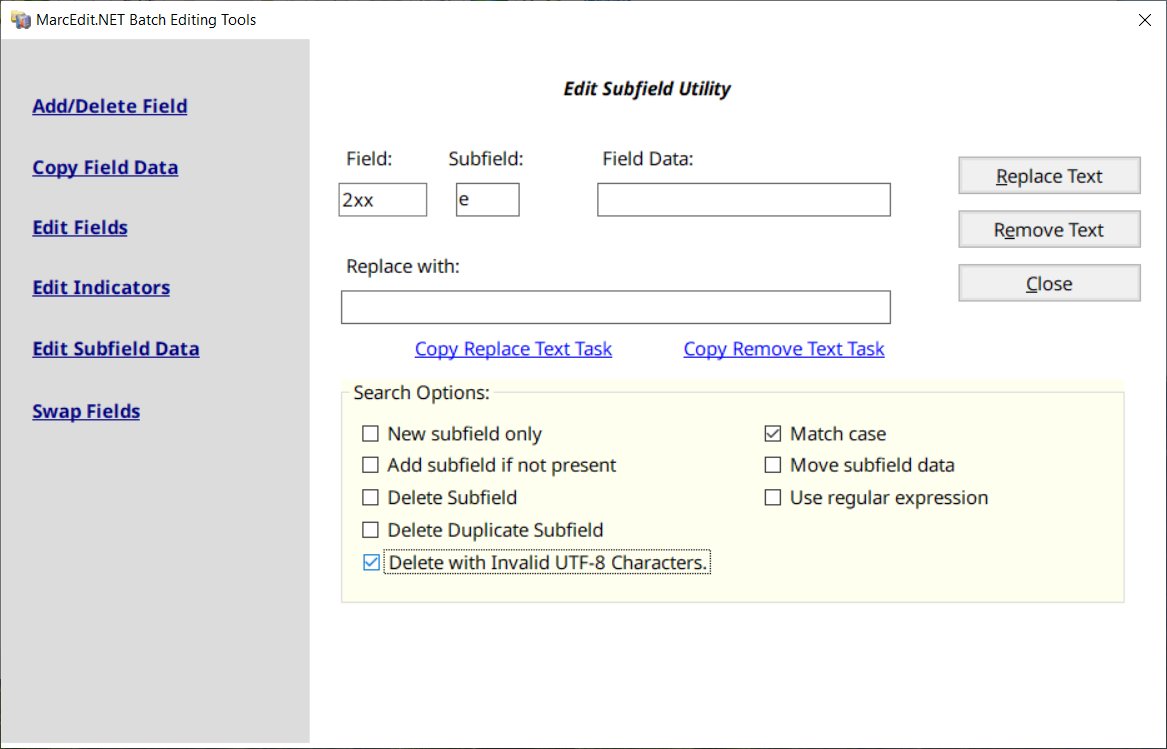
Delete Subfields
Added to the Edit Subfield Utility – I’ve included an option to evaluate and delete a subfield if invalid character set data is encountered.
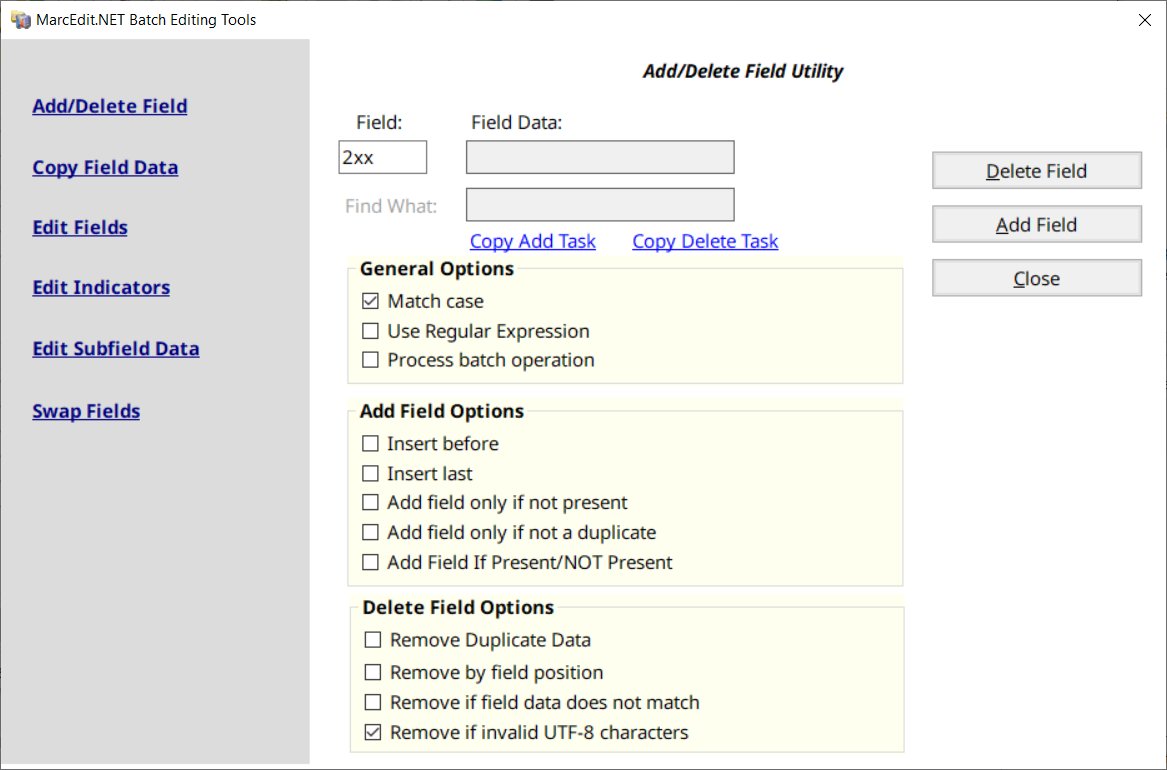
Delete Fields
Added to the Add/Delete Field Utility – I’ve included an option to evaluate and delete a field if invalid character set data is encountered.
Delete Records
Added to the Delete Records tool within the MarcEditor – I’ve included an option to delete a record if a field or field group has been identified as having invalid character set data. Additionally, this tool will create a second file in the same directory as the file being processed, that will contain the deleted records in a file structured as: [name of original file]_bad_yyyyMMddhhmmss.mrk
Caveat Emptor
Hopefully, the above sounds useful. I think it will be. There have been many times where I wish I had these tools readily at my fingertips. If it were only this easy. I believe I mentioned above….encodings are difficult. The Unicode specification is constantly changing, and identifying invalid characters is definitely more art than science in many cases. There are tools and established algorithms. I use these approaches. I’m also leveraging a method with the .NET Framework — CharUnicodeInfo.GetUnicodeCategory – which attempts to take a character and break it down into its character classification. When a character isn’t classified – that’s usually a good indicator that it’s not valid. But this process won’t catch everything – but it hopefully will provide a good starting point for users vexed with these issues and in need of a tool in their toolbox to attempt to remediate them.
Conclusion
My hope is that these new options will give catalogers a little more control and insight into their records – specifically given how invisible character encoding issues often are. And maybe too, by shedding light on this most vexing of issues, I can buy myself a little less time in cataloging purgatory as I’m sure there will come a point, somewhere, sometime, where my own contributions to keeping MARC alive and active will be held to account.
These new options will show up in MarcEdit and MarcEdit Mac in versions 7.2.210 (Windows) and 3.2.100 (Mac).
Questions, let me know.
–tr
[1] The fifth circle, illustrated by Stradanus (https://en.wikipedia.org/wiki/Inferno_(Dante)#/media/File:Stradano_Inferno_Canto_08.jpg)
#/media/File:Stradano_Inferno_Canto_08.jpg){kind=link}
Comments
9 responses to “MarcEdit: Identifying Invalid UTF-8 Data in MARC Records”
Is Georgian inherently considered invalid under the definitions you’re outlining, or is that only in context?
Not sure what you are asking — this isn’t language specific. The process is looking at code points, and then determining if the values are valid within the current Unicode tables — and then, if the high and low surrogates pairs are valid within the placement within the string. But in terms of language — the program has no idea what language is being used — honestly, that’s not important for this process.
The reason I mention Georgian is that a character from that script shows up in the examples you’ve used to illustrate the tool, and it lies outside the traditional MARC-8 range. Are codepoints outside of the UTF-8 equivalent of the MARC-8 range considered invalid automatically?
No, this process has nothing to do with marc8, it’s strictly about character validity. In this case, the high low surrogate pairs are invalid, so they are invalid characters (they cannot exist in their paired state)
Got it, sounds helpful, thanks! Where would you like to see improvement in the “lackluster font development”?
Hi! How are “current Unicode tables” defined? Are you checking for assigned characters, not just formally valid UTF-8?
Also, would that exclude private use text?
.NET 4.7.2 — which the application is compiled against, includes character support (classifications) for all unicode values defined up to the Unicode 11 tables. There is a secondary process that does a secondary check that will utilize the unicode tables defined by the Operating system. Currently, in Windows 10 and Catalina, that is Unicode 13. As long as the character is defined within the specification, the tool is able to classify the character. If the code point in use is outside of those tables — then it is unclassified — at that point, the tool will assess its potential for validity by looking at surrogate relationships and where the code falls within the tables.
So, validation will be as good as the operating system support of the Unicode specification beyond table 11.
–tr
if I may, I’d be cautious of this, or make it a lesser warning if a codepoint is simply unassigned, processing can easily be in advance of the OS’s support.
I understand that — but that actually not true within the context of MARC records. Most additions to the Unicode specification as of late, fall way outside of characters that would be valid within the context of our metadata. Since this tool is specific to a library context, the process is specifically designed for use within that space.
At the same time — these are just warnings. Within the validation — users are just given both warnings and context. If they want to move forward, they have tools to remove the data. This is why I’ve noted above, character encodings are hard — but within the particular use case that this process is situated, its unlikely characters not supported by the operating system, would be valid for use — libraries tend to not be that far out on the bleeding edge.