One of the tenants behind LibraryFind has always been that LibraryFind would only query materials that provide some kind of standard search protocol. However, there are many sites that provide API access, but it’s no a standard api access like OpenSearch for example. For example, a user wanting to query Yahoo or Flickr (where many libraries are starting to build collections) would have previously been unable to use LibraryFind to query these resources. However, that will change with LibraryFind 0.9. LibraryFind 0.9 introduces a custom connectors framework, that will allow users (including OSU) to develop custom connectors to resources that utilize stable, formalized APIs within LibraryFind.
Configuring these new resources is easy. In the collection administration screen (note, this might change slightly), a user would simply note that the connection type is connector, and then name the connector in the Host area. From there, the user doesn’t need to define any other elements (though you can).
Admin Interface Example:
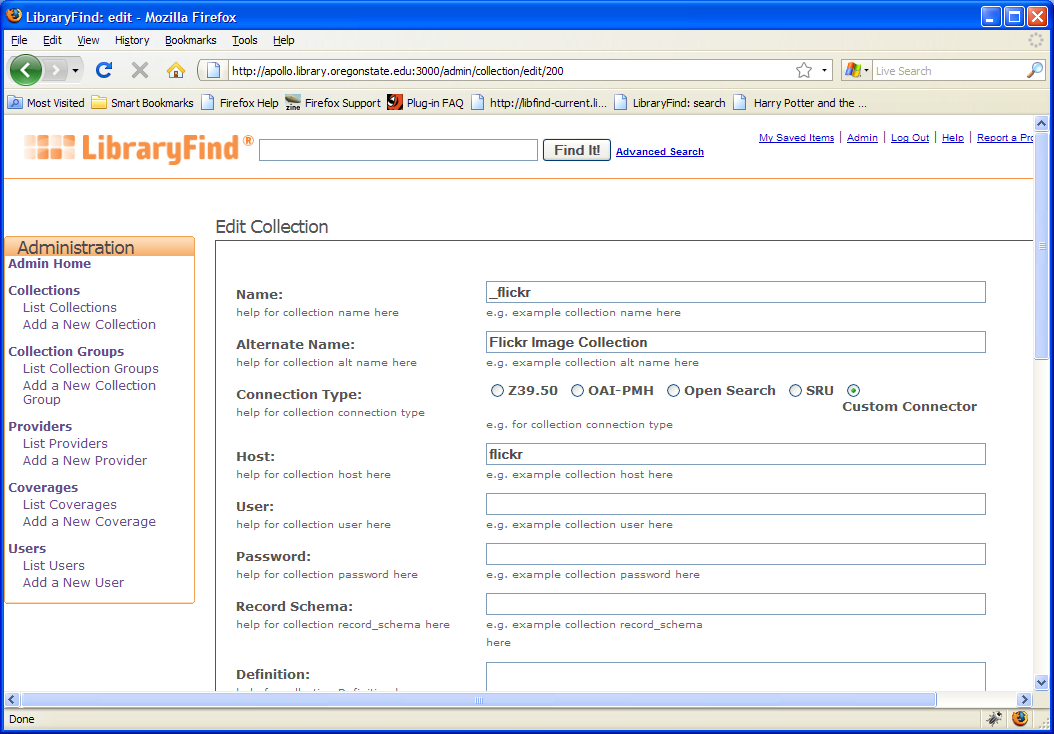
Once set, the application will utilize the connector as any other standard search class. So far example, I created a test group and queried my name using our IR, Flickr and Yahoo. Using these elements, I retrieve the following:
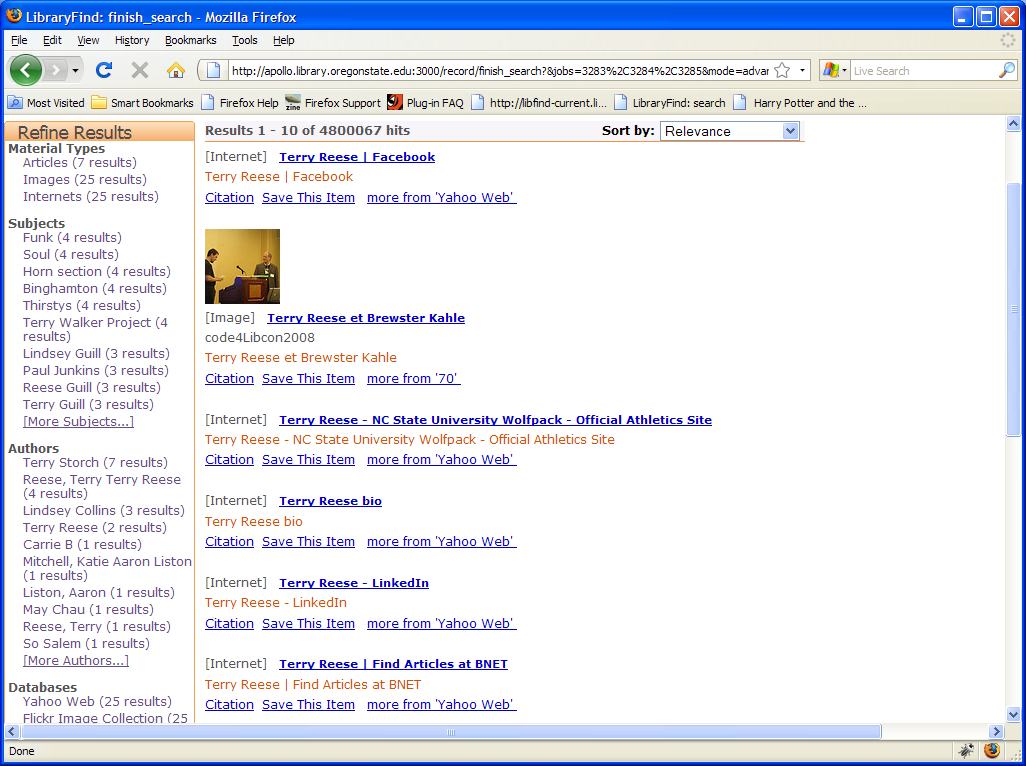
Here you can see an integration of Internet resources (from yahoo), images (from flickr) and Articles (our IR). Bringing Internet resources into the results complicates relevancy ranking (in part because there is so little metadata about the items being retrieved), but that’s something that I’ll worry about as we start to work with these items within the results set.
So how will this work. Well, I thought about going the plugin route (since Rails already provides a good model), but instead decided that I wanted to keep these custom search classes near the predefined search classes. So, in the environment.rb file, I defined an additional load_path under models (custom_connectors). Within this directory, users can drop their home made custom connectors for use by the application.
The connectors themselves must use the same format as the general search connector. Within the directory, I’ll include an example connector, but in a nutshell, the code generally looks like the following:
1: # LibraryFind - Quality find done better.
2: # Copyright (C) 2007 Oregon State University
3: #
4: # This program is free software; you can redistribute it and/or modify it under
5: # the terms of the GNU General Public License as published by the Free Software
6: # Foundation; either version 2 of the License, or (at your option) any later
7: # version.
8: #
9: # This program is distributed in the hope that it will be useful, but WITHOUT
10: # ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
11: # FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
12: # this program; if not, write to the Free Software Foundation, Inc., 59 Temple
13: # Place, Suite 330, Boston, MA 02111-1307 USA
14: #
15: # Questions or comments on this program may be addressed to:
16: #
17: # LibraryFind
18: # 121 The Valley Library
19: # Corvallis OR 97331-4501
20: #
21: # http://libraryfind.org
22:
23: require 'rubygems'
24:
25: class ExampleSearchClass < ActionController::Base
26: @cObject = nil
27: @pkeyword = ""
28: @feed_id = 0
29: @search_id = 0
30:
31: logger.debug("collection entered")
32: @cObject = _collect
33: @pkeyword = _qstring.join(" ")
34: @feed_id = _collect.id
35: @search_id = _last_id
36: begin
37: #perform the search
38: results = your_search(@pkeyword, _max.to_i)
39: rescue Exception => bang
40: if _action_type != nil
41: _lxml = ""
42: logger.debug("ID: " + _last_id.to_s)
43: return my_id, 0
44: else
45: return nil
46: end
47: end
48:
49: if results != nil
50: begin
51: _lrecord = parse_yahoo(results)
52: rescue Exception => bang
53: if _action_type != nil
54: _lxml = ""
55: return my_id, 0
56: else
57: end
58: end
59:
60: _lxml = CachedSearch.build_cache_xml(_lrecord)
61:
62: if _lxml != nil: _lprint = true end
63: if _lxml == nil: _lxml = "" end
64:
65: #============================================
66: # Add this info into the cache database
67: #============================================
68: if _last_id.nil?
69: # FIXME: Raise an error
70: logger.debug("Error: _last_id should not be nil")
71: else
72: status = LIBRARYFIND_CACHE_OK
73: if _lprint != true
74: status = LIBRARYFIND_CACHE_EMPTY
75: end
76: end
77: else
78: _lxml = ""
79: end
80:
81: if _action_type != nil
82: if _lrecord != nil
83: return my_id, _lrecord.length
84: else
85: return my_id, 0
86: end
87: else
88: return _lrecord
89: end
90: end
91:
92: def self.strip_escaped_html(str, allow = [''])
93: str = str.gsub("&lt;", "<")
94: str = str.gsub("&gt;", ">")
95: str = str.gsub("<", "<")
96: str = str.gsub(">", ">")
97: str.strip || ''
98: allow_arr = allow.join('|') << '|\/'
99: str = str.gsub(/<(\/|\s)*[^(#{allow_arr})][^>]*>/, ' ')
100: str = str.gsub("<", "<")
101: str = str.gsub(">", ">")
102: return str
103:
104: def self.your_search(query, max)
105: xml = yourquery(query, max)
106: _objRec = RecordSet.new()
107: _title = ""
108: _authors = ""
109: _description = ""
110: _subjects = ""
111: _publisher = ""
112: _link = ""
113:
114: #Parse your data
115: _start_time = Time.now()
116:
117: #loop through your results and populate Record.
118: nodes.each { |item|
119: begin
120: record = Record.new()
121: record.vendor_name = @cObject.alt_name
122: record.ptitle = normalize(_yourtitle)
123: record.title = normalize(_yourtitle)
124: record.atitle = ""
125: record.issn = ""
126: record.isbn = ""
127: record.abstract = normalize(_yourdescription)
128: record.date = ""
129: record.author = normalize(_yourauthors)
130: record.link = ""
131: record.doi = ""
132: record.openurl = ""
133: record.direct_url = normalize(_yourlink)
134: record.static_url = ""
135: record.subject = normalize(_yoursubjects)
136: record.publisher = ""
137: record.callnum = ""
138: record.vendor_url = normalize(@cObject.vendor_url)
139: record.material_type = normalize(@cObject.mat_type)
140: record.volume = ""
141: record.issue = ""
142: record.page = ""
143: record.number = ""
144: record.start = _start_time.to_f
145: record.end = Time.now().to_f
146: record.hits = _hit_count
147: _record[_x] = record
148: _x = _x + 1
149: rescue Exception => bang
150: logger.debug(bang)
151: next
152: end
153: }
154: return _record
155:
156: end
157:
158: def self.normalize(_string)
159: return _string.gsub(/\W+$/,"") if _string != nil
160: return ""
161: #_string = _string.gsub(/\W+$/,"")
162: #return _string
163: end
164:
165: end
However, within the custom_connectors directory, there will at least be the yahoo_search_class.rb and the flickr_search_class.rb which will provide sample code sets for users wanting to see how a custom_connector may be created.
Anyway, as I continue marching towards the release of the 0.9 code-base, I’ll continue to post some of the new functionality that folks should expect to see in the new version.
–TR